Loading...

TL;DR: FPSAttention is a training-aware FP8 quantization and sparsity co-design for video diffusion models that achieves up to 7.09x kernel speedups and 4.96× E2E speedups without quality loss by aligning 3D tile granularity, denoising-step adaptation, and hardware-efficient kernels.

Diffusion generative models have become the standard for producing high-quality, coherent video content, yet their slow inference speeds and high computational demands hinder practical deployment. Although both quantization and sparsity can independently accelerate inference while maintaining generation quality, naively combining these techniques in existing training-free approaches leads to significant performance degradation, as they fail to achieve proper joint optimization. We introduce FPSAttention, a novel training-aware co-design of FP8 quantization and Sparsity for video generation, with a focus on the 3D bi-directional attention mechanism. Our approach features three key innovations:
Trained on Wan2.1's 1.3B and 14B models and evaluated on the VBench benchmark, FPSAttention achieves a 7.09× kernel speedup for attention operations and a 4.96× end-to-end speedup for video generation compared to the BF16 baseline at 720p resolution — without sacrificing generation quality.
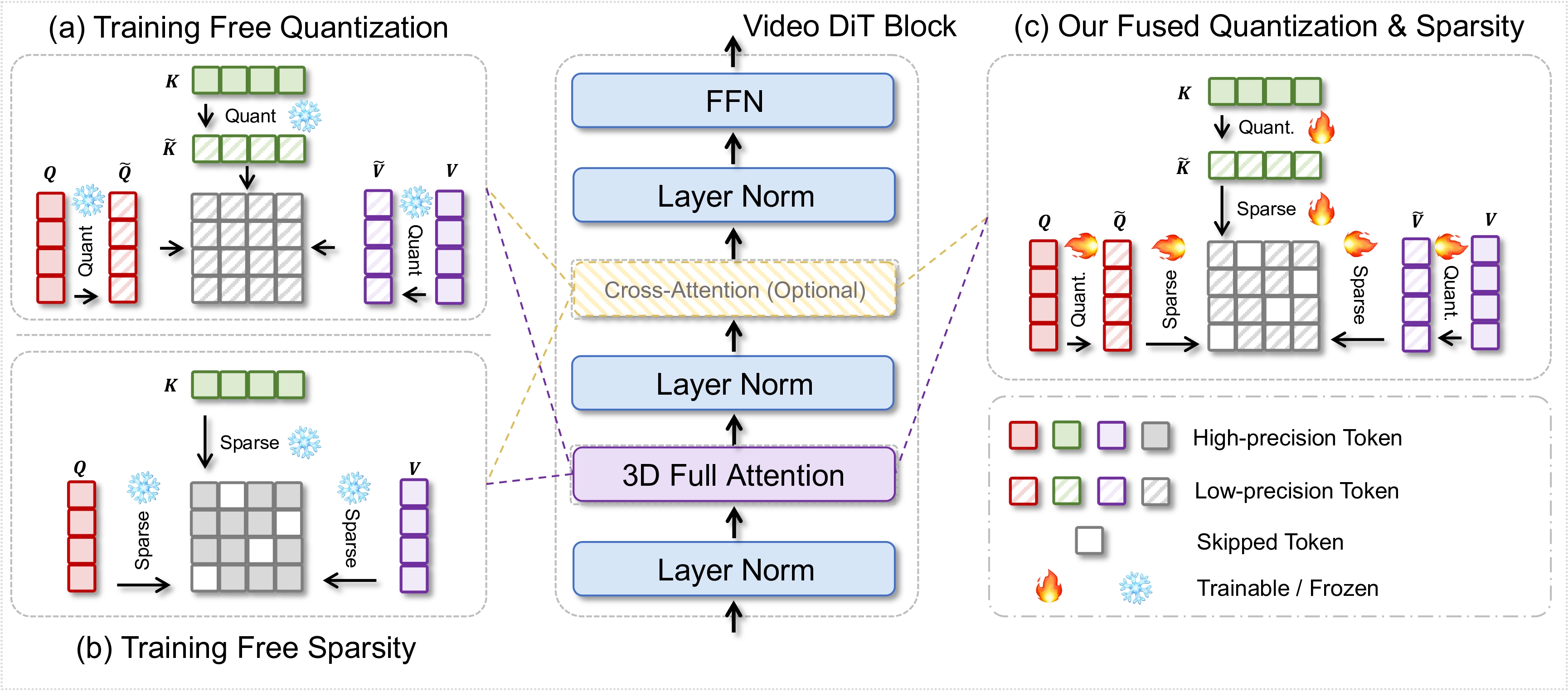
To address the efficiency challenge, numerous acceleration methodologies have been proposed, among which quantization and sparsity have emerged as predominant techniques. Quantization reduces numerical precision (e.g., FP32 to INT8 or FP8), thereby decreasing the memory footprint and enabling faster computations (Figure 1(a)). Recent post-training quantization (PTQ) methods like SageAttention quantize attention modules into INT8 using calibration strategies, providing moderate acceleration at the cost of reduced generation quality. Compared to INT8, the emerging FP8 format offers a wider dynamic range, facilitating both training and inference. Nevertheless, training-free FP8 quantization, despite its theoretical advantages, introduces significant quantization errors that degrade model performance. Apart from quantization, sparsity techniques address the quadratic computational complexity of 3D full attention by selectively skipping computations (Figure 1(b)). Representative approaches include Sparse-VideoGen, which implements per-head spatial-temporal masks aligned with GPU blocks; SpargeAttn, which employs a two-stage filtering mechanism; and Sliding Tile Attention (STA), which leverages local 3D sliding windows with kernel-level optimizations.
In this paper, we introduce FPSAttention, as shown in Figure 1(c), a novel training-aware co-design framework that synergistically integrates FP8 quantization and structured sparsity for 3D attention in video DiTs.
Our technique integrates algorithmic innovation with hardware-conscious kernel optimization to enhance the efficiency of video DiTs. This section begins by establishing fundamental concepts essential to our methodology. Subsequently, we introduce the architecture of our proposed FPSAttention, detailing its two primary algorithmic contributions: a unified tile-wise quantization and sparse attention mechanism, and a denoising step-aware strategy for dynamic adaptation of quantization and sparsity hyperparameters. Finally, we outline our hardware-optimized kernel implementation that plays a crucial role in translating theoretical computational savings into practical efficiency gains. Figure 2 provides a high-level conceptual overview of our FPSAttention framework.
Building upon FP8 quantization and tiled attention techniques, we introduce FPSAttention, a Joint Tile-wise FP8 Quantization and Sparse Attention mechanism that synergistically optimizes computational efficiency and perceptual accuracy in video DiTs.
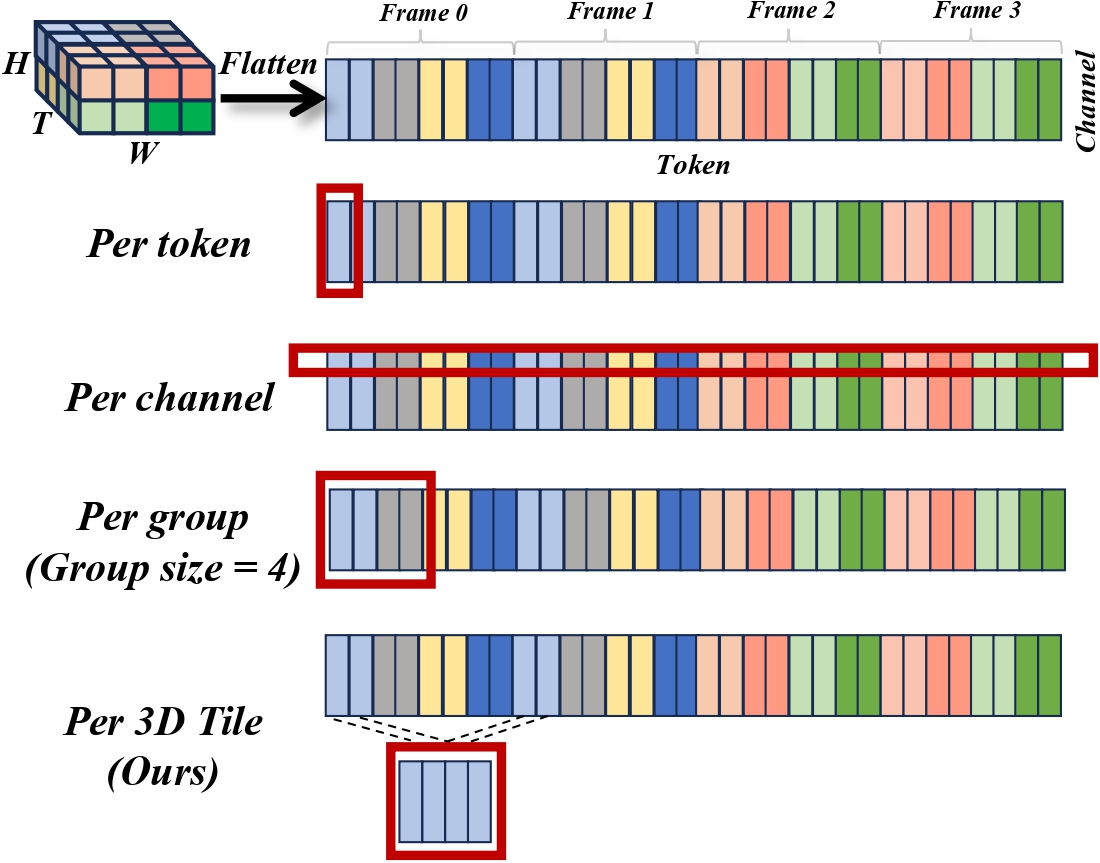
Our tile-wise granularity approach (Figure 3, last row) is motivated by three primary considerations. First, it offers an optimal accuracy-efficiency trade-off compared to conventional methods (per-token, per-channel, per-group; Figure 3, first three rows) that often fail to align with underlying hardware architectures. While per-group quantization provides a reasonable balance, it frequently overlooks GPU compute tile patterns, thereby reducing hardware utilization efficiency. Second, our approach maintains full compatibility with the STA sparsity design, allowing seamless integration of quantization and sparsity optimizations at matching granularity. Third, our tile-wise design exhibits superior hardware compatibility, aligning precisely with compute tiles in optimized kernels such as FlashAttention, which enables direct translation of theoretical computational savings into practical speedups.
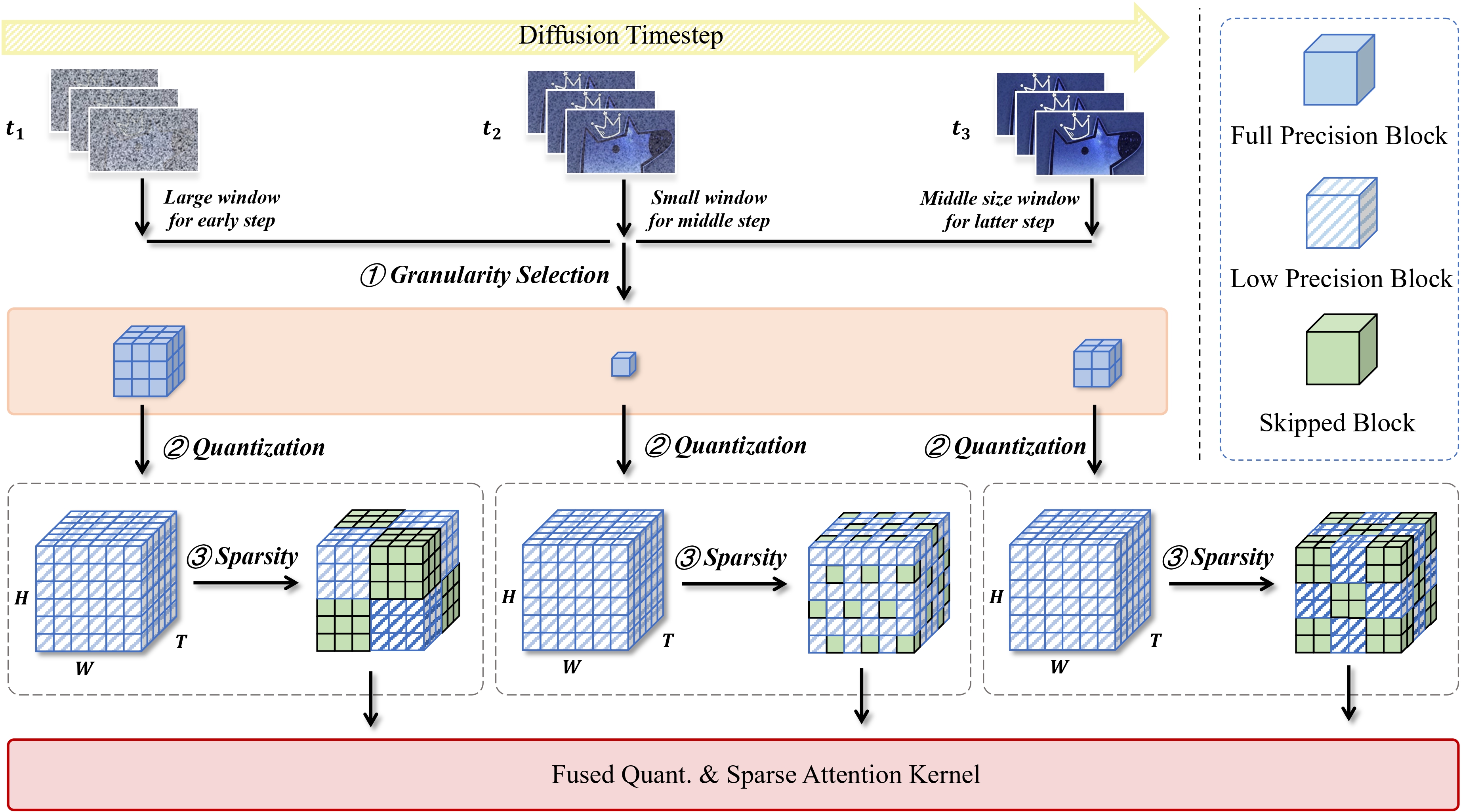
As as illustrated in Figure 4, video DiTs exhibit varying sensitivity to numerical precision and sparsity levels throughout the diffusion process. Specifically, early and late denoising steps demonstrate greater tolerance to coarser quantization and higher sparsity, whereas intermediate steps demand finer numerical precision and lower sparsity. This also suggests that diffusion models can intrinsically correct the approximation errors of attention, which motivates our training-aware scheme to mitigate the training-inference gap. Based on these observations, we propose an adaptive, denoising step-aware compression schedule, for both training and inference. We adjust the quantization granularity g(t) and sparsity window size W(t) based on the denoising step t.
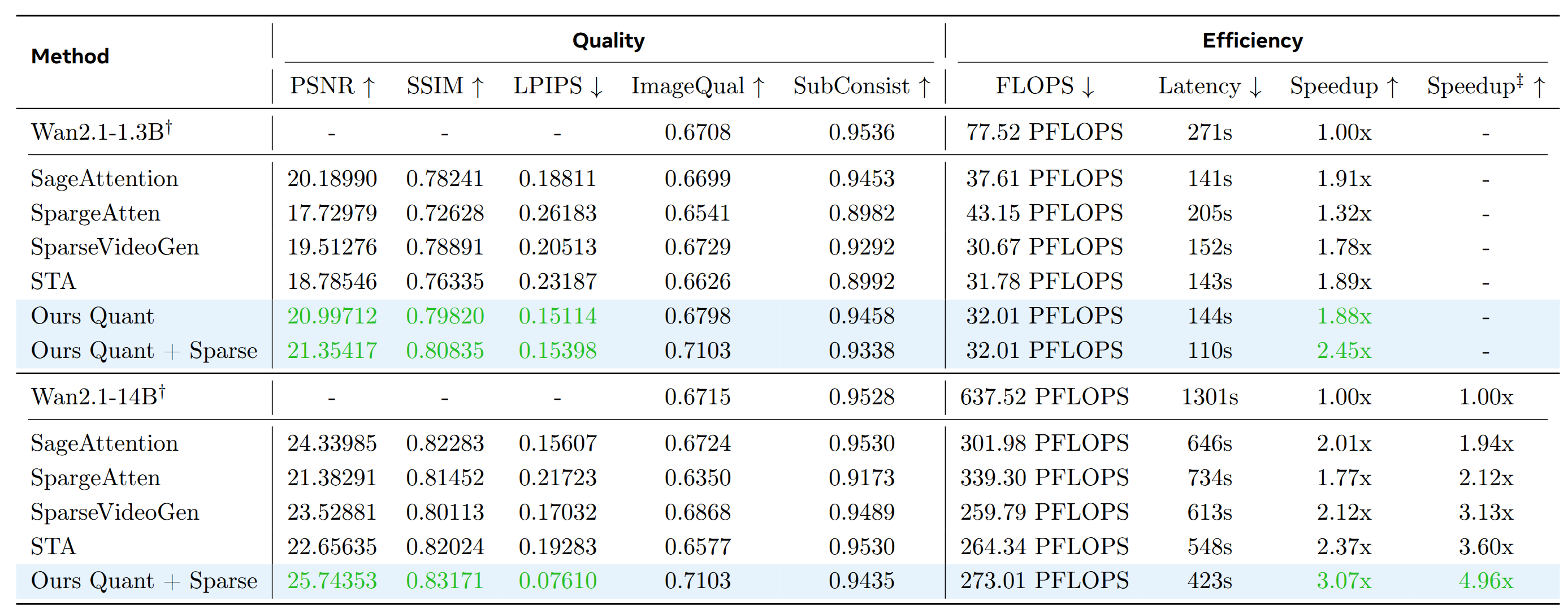
We compare FPSAttention with several state-of-the-art optimization methods, as shown in Table 1. Our baselines include sparsity-based approaches (SparseVideoGen and STA), quantization methods (SageAttention), and hybrid approaches (SpargeAtten, a training-free method that jointly applies attention sparsification and activation quantization). As demonstrated in Table 1, FPSAttention achieves superior performance across all quality metrics. Particularly notable is the average PSNR of 25.74353 on the Wan2.1-14B model, significantly outperforming all baseline methods. This objective metric confirms FPSAttention's ability to generate videos with exceptional fidelity to reference images. Furthermore, FPSAttention maintains excellent performance on perceptual metrics, with high Video Quality (0.7103) and strong spatial-temporal consistency (0.9435) on the VBench evaluation. Interestingly, after joint training, FPSAttention exhibits a slight increase in VBench scores, while also demonstrate performance improvements when trained with structured sparsity—potentially driven by the inductive bias of locality. These results validate that our joint sparsity and quantization approach preserves visual quality while substantially improving computational efficiency.
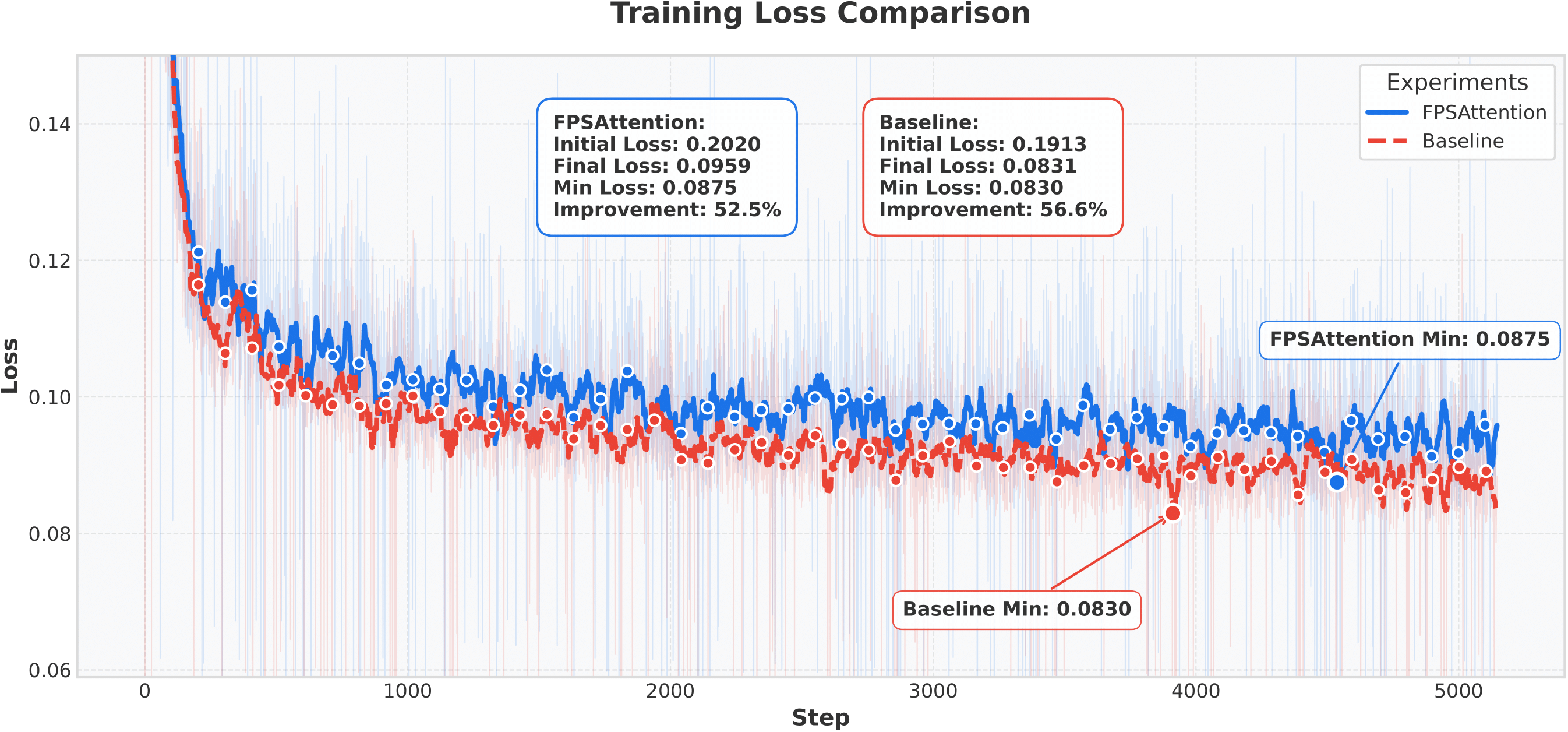
Joint FP8 quantization and structured sparsity initially increases training loss by 15% compared to full-precision Wan2.1 baseline (Figure 7). We mitigate these challenges through adaptive learning rate scheduling and gradient accumulation techniques. After 2,000 steps, loss convergence trajectories become nearly identical (<2% difference), confirming that our FP8 sparse attention preserves critical information pathways despite bitwidth and sparsity constraints.